
💡 Building AI Applications in 2026? Facing These Challenges?
As AI adoption continues to accelerate in 2026, many developers and companies encounter the same problems:
Too many model APIs to integrate and maintain
Rising token costs that seem impossible to control
Service disruptions when a model provider experiences downtime
No centralized visibility into usage, latency, and spending
If any of these sound familiar, it may be time to consider a better approach.
Meet OpenLLM — a powerful AI gateway and LLM routing platform designed to simplify large-scale AI development.
1. What Is OpenLLM?
1.1 Platform Overview
OpenLLM is a professional AI gateway and LLM routing platform.
In simple terms, OpenLLM unifies more than 300 large language models from leading AI providers behind a single API interface. Instead of integrating each provider separately, developers can access all supported models through one consistent endpoint.
This means no more switching between OpenAI documentation today and Anthropic documentation tomorrow.
Core Value Proposition
OpenLLM helps organizations:
Connect to 300+ AI models through a unified API
Deploy and manage production-grade AI applications efficiently
Reduce integration complexity
Improve reliability and cost efficiency
Scale AI infrastructure with confidence
1.2 Problems OpenLLM Solves
Imagine building an application that needs access to multiple LLM providers.
😱 Without OpenLLM
You may need to:
Integrate APIs from OpenAI, Anthropic, DeepSeek, Zhipu AI, and many others
Handle different authentication methods and API formats
Build custom error handling for every provider
Monitor costs separately across platforms
Manage provider outages manually
Continuously optimize model selection and spending
The engineering overhead quickly becomes overwhelming.
✨ With OpenLLM
OpenLLM centralizes everything behind a single platform, dramatically reducing complexity while improving reliability and performance.
2. Core Features
2.1 Unified API Access
OpenLLM provides a single API endpoint that supports more than 300 models from over 30 leading AI providers.
Supported Categories
Global Models
OpenAI GPT Series
Anthropic Claude Series
Leading Chinese Models
DeepSeek
GLM (Zhipu AI)
Qwen (Alibaba)
Open-Source Models
Llama Family
Mistral Models
And many more
One API. Hundreds of models.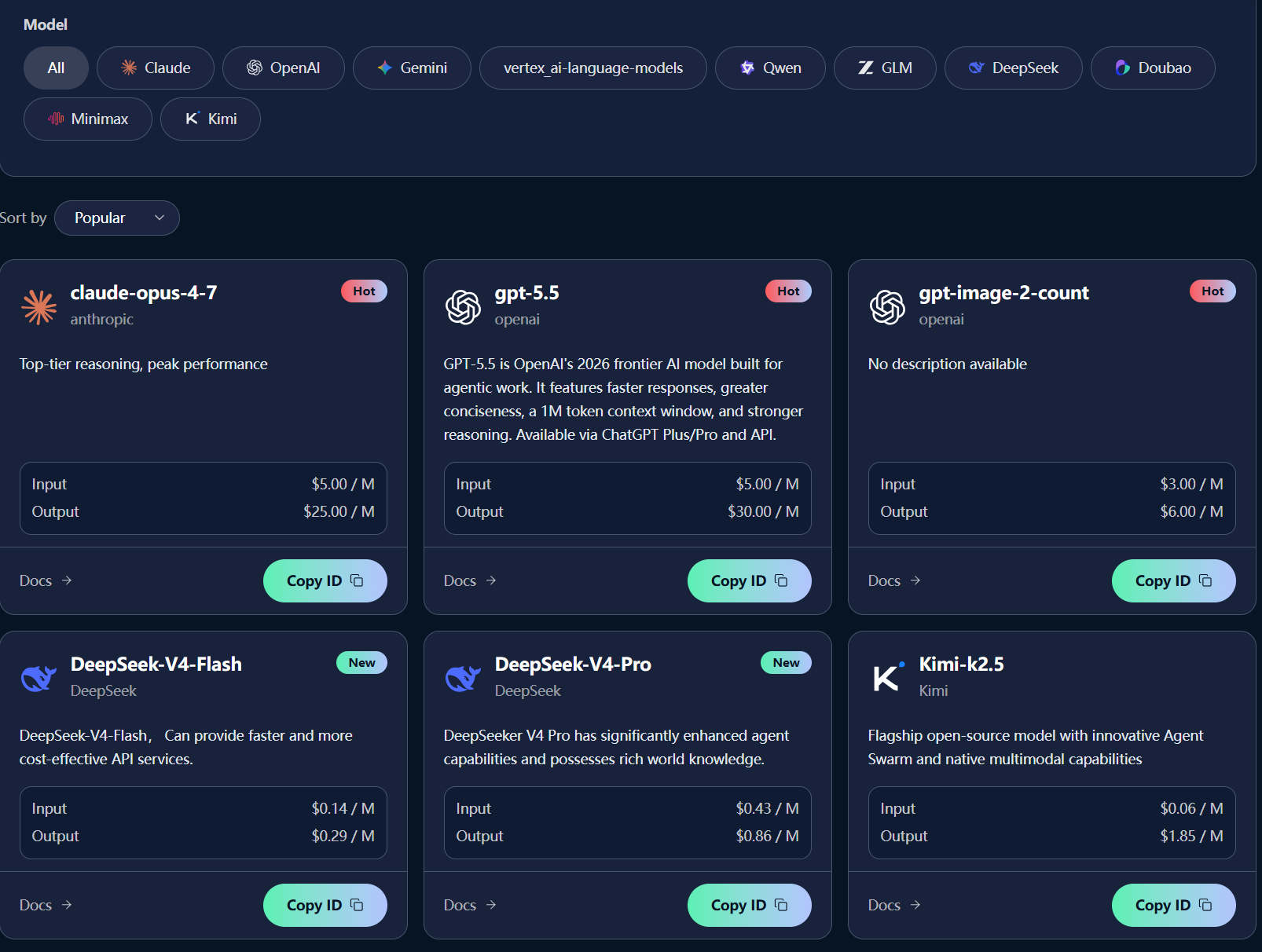
2.2 Intelligent Routing
Semantic Routing
OpenLLM can automatically select the most suitable model based on request complexity and intent.
Examples:
Simple questions → lower-cost models
Complex reasoning → advanced models
Code generation → code-specialized models
This ensures optimal performance while minimizing costs.
Automatic Failover
If an upstream provider experiences downtime or degraded performance, OpenLLM automatically switches to backup models.
This capability is especially valuable for production environments where reliability is critical.
A/B Testing & Prompt Versioning
OpenLLM supports:
Model A/B testing
Prompt experimentation
Routing strategy optimization
Teams can continuously improve output quality using real-world traffic.
2.3 Performance & Cost Optimization
Context Caching
Persistent context storage significantly reduces token consumption.
For repeated or similar requests, OpenLLM can return cached responses without invoking the underlying model again.
Benefits include:
Lower API costs
Faster responses
Reduced token usage
Edge Caching
Global edge caching helps:
Improve cold-start performance
Reduce latency
Enhance user experience for international audiences
2.4 Massive Scalability
OpenLLM automatically scales infrastructure to handle millions of concurrent requests.
Whether your application serves hundreds or millions of users, the platform can scale accordingly.
2.5 Streaming Responses
OpenLLM supports real-time streaming output, enabling:
More responsive chat experiences
Faster perceived performance
Improved user engagement
Users can start reading responses before generation is complete.
3. Enterprise-Grade Management Features
3.1 Unified Observability Dashboard
OpenLLM provides comprehensive monitoring and analytics.
Cost Analytics
Track token usage by:
Model
Project
Team
Time range
Latency Monitoring
Monitor response times in real time.
Usage Statistics
Understand model popularity and usage patterns.
Health Alerts
Receive notifications when services encounter issues.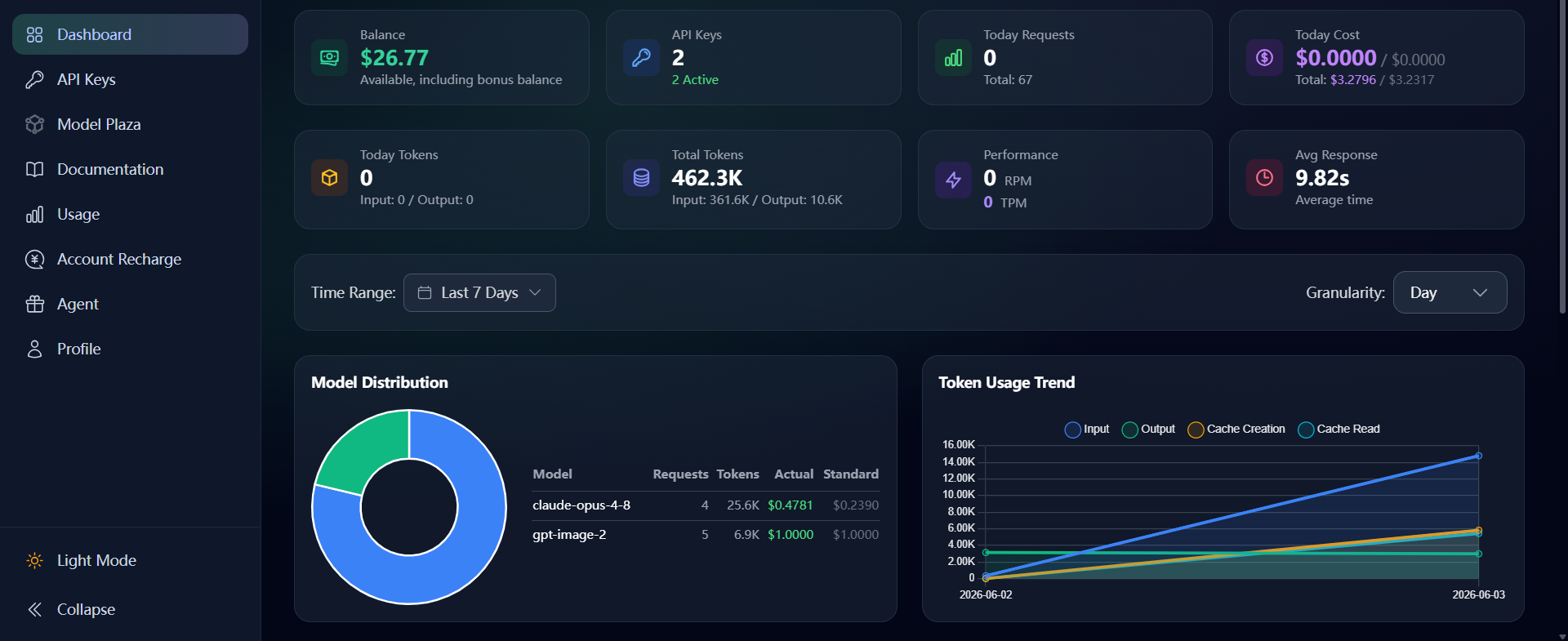
3.2 Access Control & Project Isolation
Enterprise customers can leverage:
Sub-Key Management
Generate dedicated API keys for:
Teams
Applications
Departments
Budget Controls
Set spending limits to avoid unexpected costs.
Project Isolation
Keep configurations and usage data separate across projects.
Role-Based Access Control
Support for:
Administrators
Developers
Observers
Custom roles
Audit Logs
Track all platform activities for compliance purposes.
Environment Separation
Maintain independent:
Development environments
Testing environments
Production environments
3.3 Security & Compliance
OpenLLM is designed with enterprise security in mind.
Security Features
TLS 1.3 encryption
Secure API key management
Key rotation support
Fine-grained permission controls
Minimal logging of sensitive data
Organizations can confidently deploy AI workloads while maintaining compliance requirements.
4. Cost Advantages
4.1 Pay-As-You-Go Pricing
OpenLLM uses a transparent token-based pricing model.
You only pay for actual usage.
Benefits include:
No hidden fees
Permanent account balance validity
Predictable billing
4.2 Recharge Bonuses
The platform offers tiered recharge incentives.
The larger the recharge amount, the larger the bonus credits provided.
This significantly reduces effective usage costs for businesses and power users.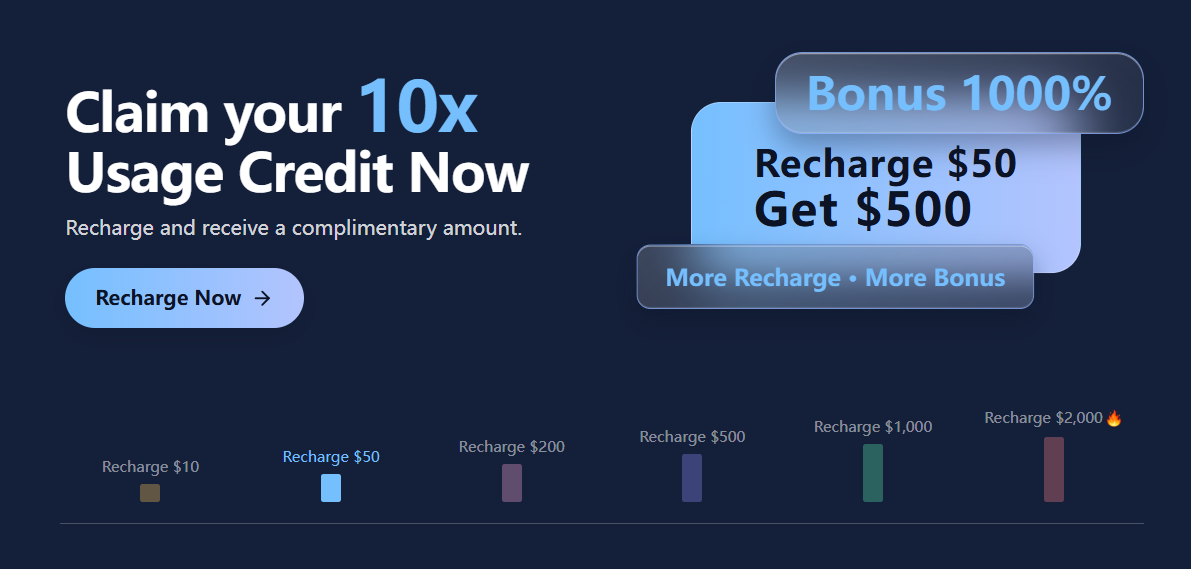
4.3 Hidden Cost Savings
Beyond API pricing, OpenLLM helps reduce:
Development Costs
No need to build integrations for every model provider.
Operations Costs
Built-in rate limiting, routing, and failover reduce infrastructure burden.
Experimentation Costs
A/B testing enables faster optimization and decision-making.
5. Who Should Use OpenLLM?
Developers & Engineers
Ideal for:
Full-stack developers
Backend engineers
AI engineers
Platform architects
Startups & Small Teams
Gain enterprise-grade AI infrastructure without building it yourself.
Perfect for teams that need:
Fast deployment
Lower costs
Reliable scalability
Enterprise Technology Leaders
Suitable for:
CTOs
ML Platform Leads
DevOps Managers
Benefits include centralized governance, cost control, and compliance management.
Product & Growth Teams
Use A/B testing and routing optimization to improve:
User experience
Conversion rates
Product performance
6. Real-World Use Cases
Intelligent Customer Support
Challenge
Handle both simple and complex customer inquiries efficiently.
Solution
Semantic routing
Cost-optimized model selection
Automatic failover
Result
Lower costs and high availability.
Content Generation Platforms
Challenge
Different content types require different models.
Solution
Model A/B testing
Prompt optimization
Context caching
Result
Higher content quality with reduced token consumption.
Global Enterprise Applications
Challenge
Serve worldwide users with low latency.
Solution
Edge caching
Streaming responses
Environment isolation
Result
Fast, reliable experiences for users globally.
7. OpenLLM vs Alternatives
Feature | OpenLLM | Traditional Self-Built Solution | Typical AI Gateway |
|---|---|---|---|
Supported Models | 300+ | Manual Integration | Usually 50-100 |
Intelligent Routing | ✅ Advanced | ❌ Custom Development | ⚠️ Limited |
Context Caching | ✅ Built-in | ❌ Custom Development | ⚠️ Partial |
Auto Scaling | ✅ Millions of Requests | ⚠️ Complex Infrastructure | ⚠️ Limited |
Enterprise Management | ✅ Complete Suite | ❌ Build Yourself | ⚠️ Partial |
Cost Transparency | ✅ Clear Pricing | ⚠️ Hidden Costs | ⚠️ Varies |
Deployment Speed | ✅ Immediate | ❌ Weeks of Development | ✅ Moderate |
8. Getting Started
Quick Setup
Visit https://openllm.shop
Create an account
Generate an API key
Copy your preferred model ID
Configure your AI application
You're ready to build.
Best Practices
Create separate projects for development, testing, and production
Configure budget alerts
Enable context caching
Set up failover routing
Monitor usage regularly
9. User Feedback

Startup CTO
"OpenLLM allowed our small team to launch enterprise-grade AI features without building complex infrastructure. Intelligent routing alone saved us a significant amount in API costs."
ML Platform Lead
"The observability dashboard provides clear insights into project costs and model performance, helping us make better decisions."
SaaS Engineering Manager
"Automatic failover saved us during a provider outage. OpenLLM seamlessly switched to backup models and our users never noticed."
10. Final Thoughts
Why Choose OpenLLM?
OpenLLM delivers five key advantages:
✅ Unified Access
One API endpoint for 300+ AI models.
✅ Intelligent Routing
Semantic routing and automatic failover.
✅ Cost Optimization
Context caching can reduce token consumption by up to 80%.
✅ Enterprise Management
Comprehensive monitoring, permissions, auditing, and project isolation.
✅ Massive Scalability
Automatic scaling for production-grade workloads.
Recommended For
Multi-model AI applications
Production AI systems
Cost-conscious organizations
Fast-moving development teams
Start Today
Ready to simplify AI infrastructure?
🚀 Get Started in Four Steps
Visit https://openllm.shop
Create a free account
Generate an API key
Launch your first AI-powered application
New users may also qualify for exclusive promotional credits and bonuses.
Frequently Asked Questions
Which AI providers are supported?
OpenLLM integrates with more than 30 leading providers, including OpenAI, Anthropic, DeepSeek, Zhipu AI, Qwen, and many others, supporting over 300 models.
How is pricing calculated?
Pricing is based on actual input and output token usage. Account balances never expire, and recharge bonuses are available.
How is data security handled?
OpenLLM uses TLS 1.3 encryption, secure key management, key rotation support, and fine-grained permission controls.
Can OpenLLM be self-hosted?
OpenLLM primarily offers a SaaS platform. Enterprise customers with special requirements can contact the team regarding custom deployment options.
What support is available?
OpenLLM provides SLA-backed reliability, health monitoring, and priority technical support for enterprise customers.